| JoPano: Unified Panorama Generation via Joint Modeling Wancheng Feng*, Chen An*, Zhenliang He✉, Meina Kan, Shiguang Shan, Lukun Wang   ⮟ Abstract ⮝ Abstract | Paper | Project | ⮟ Bib ⮝ Bib |
Panorama generation has recently attracted growing interest in the research community, with two core tasks, text-to-panorama and view-to-panorama generation. However, existing methods still face two major challenges: their U-Net-based architectures constrain the visual quality of the generated panoramas, and they usually treat the two core tasks independently, which leads to modeling redundancy and inefficiency. To overcome these challenges, we propose a joint-face panorama (JoPano) generation approach that unifies the two core tasks within a DiT-based model. To transfer the rich generative capabilities of existing DiT backbones learned from natural images to the panorama domain, we propose a Joint-Face Adapter built on the cubemap representation of panoramas, which enables a pretrained DiT to jointly model and generate different views of a panorama. We further apply Poisson Blending to reduce seam inconsistencies that often appear at the boundaries between cube faces. Correspondingly, we introduce Seam-SSIM and Seam-Sobel metrics to quantitatively evaluate the seam consistency. Moreover, we propose a condition switching mechanism that unifies text-to-panorama and view-to-panorama tasks within a single model. Comprehensive experiments show that JoPano can generate high-quality panoramas for both text-to-panorama and view-to-panorama generation tasks, achieving state-of-the-art performance on FID, CLIP-FID, IS, and CLIP-Score metrics. |
@article{JoPano2025,
title={JoPano: Unified Panorama Generation via Joint Modeling},
author={Wancheng Feng, Chen An, Zhenliang He, Meina Kan, Shiguang Shan, Lukun Wang},
journal={arXiv preprint arXiv:2512.06885},
year={2025}
} |
 | Jodi: Unification of Visual Generation and Understanding via Joint Modeling Yifeng Xu, Zhenliang He✉, Meina Kan, Shiguang Shan, Xilin Chen  ⮟ Abstract ⮝ Abstract | Paper | Project | Joint-1.6M Dataset | ⮟ Bib ⮝ Bib |
Visual generation and understanding are two deeply interconnected aspects of human intelligence, yet they have been traditionally treated as separate tasks in machine learning. In this paper, we propose Jodi, a diffusion framework that unifies visual generation and understanding by jointly modeling the image domain and multiple label domains. Specifically, Jodi is built upon a linear diffusion transformer along with a role switch mechanism, which enables it to perform three particular types of tasks: (1) joint generation, where the model simultaneously generates images and multiple labels; (2) controllable generation, where images are generated conditioned on any combination of labels; and (3) image perception, where multiple labels can be predicted at once from a given image. Furthermore, we present the Joint-1.6M dataset, which contains 200,000 high-quality images collected from public sources, automatic labels for 7 visual domains, and LLM-generated captions. Extensive experiments demonstrate that Jodi excels in both generation and understanding tasks and exhibits strong extensibility to a wider range of visual domains. |
@article{xu2025jodi,
title={Jodi: Unification of Visual Generation and Understanding via Joint Modeling},
author={Xu, Yifeng and He, Zhenliang and Kan, Meina and Shan, Shiguang and Chen, Xilin},
journal={arXiv preprint arXiv:2505.19084},
year={2025},
} |
 | CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation Yifeng Xu, Zhenliang He✉, Shiguang Shan, Xilin Chen   ⮟ Abstract ⮝ Abstract | Paper | Project | ⮟ Bib ⮝ Bib |
Recently, large-scale diffusion models have made impressive progress in text-to-image (T2I) generation. To further equip these T2I models with fine-grained spatial control, approaches like ControlNet introduce an extra network that learns to follow a condition image. However, for every single condition type, ControlNet requires independent training on millions of data pairs with hundreds of GPU hours, which is quite expensive and makes it challenging for ordinary users to explore and develop new types of conditions. To address this problem, we propose the CtrLoRA framework, which trains a Base ControlNet to learn the common knowledge of image-to-image generation from multiple base conditions, along with condition-specific LoRAs to capture distinct characteristics of each condition. Utilizing our pretrained Base ControlNet, users can easily adapt it to new conditions, requiring as few as 1,000 data pairs and less than one hour of single-GPU training to obtain satisfactory results in most scenarios. Moreover, our CtrLoRA reduces the learnable parameters by 90% compared to ControlNet, significantly lowering the threshold to distribute and deploy the model weights. Extensive experiments on various types of conditions demonstrate the efficiency and effectiveness of our method. |
@article{xu2024ctrlora,
title={CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation},
author={Xu, Yifeng and He, Zhenliang and Shan, Shiguang and Chen, Xilin},
journal={arXiv preprint arXiv:2410.09400},
year={2024}
} |
 | Precise Integral in NeRFs: Overcoming the Approximation Errors of Numerical Quadrature Boyuan Zhang, Zhenliang He✉, Meina Kan, Shiguang Shan   ⮟ Abstract ⮝ Abstract | Paper | Project | ⮟ Bib ⮝ Bib |
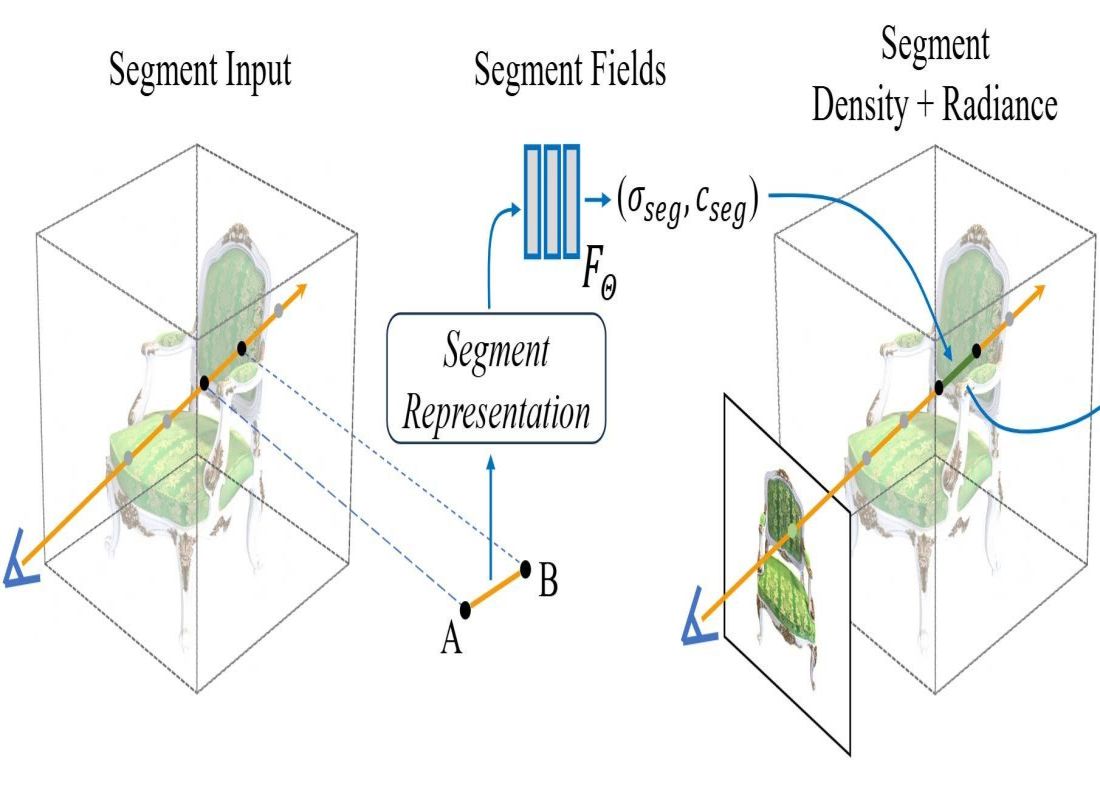
Neural Radiance Fields (NeRFs) use neural networks to translate spatial coordinates to corresponding volume density and directional radiance, enabling realistic novel view synthesis through volume rendering. Rendering new viewpoints involves computing volume rendering integrals along rays, usually approximated by numerical quadrature because of lacking closed-form solutions. In this paper, utilizing Taylor expansion, we demonstrate that numerical quadrature causes inevitable approximation error in NeRF integrals due to ignoring the parameter associated with the Lagrange remainder. To mitigate the approximation error, we propose a novel neural field with segment representation as input to implicitly model the remainder parameter. In theory, our proposed method is proven to possess the potential to achieve fully precise rendering integral, as demonstrated by comprehensive experiments on several commonly used datasets with state-of-the-art results. |
@inproceedings{zhang2025precnerf,
title={Precise Integral in NeRFs: Overcoming the Approximation Errors of Numerical Quadrature},
author={Zhang, Boyuan and He, Zhenliang and Kan, Meina and Shan, Shiguang},
booktitle={Winter Conference on Applications of Computer Vision},
year={2025}
} |
 | EigenGAN: Layer-Wise Eigen-Learning for GANs Zhenliang He, Meina Kan✉, Shiguang Shan   ⮟ Abstract ⮝ Abstract | Paper | Proof | Video | TensorFlow (Official) | PyTorch | ⮟ Bib ⮝ Bib |
Recent studies on Generative Adversarial Network (GAN) reveal that different layers of a generative CNN hold different semantics of the synthesized images. However, few GAN models have explicit dimensions to control the semantic attributes represented in a specific layer. This paper proposes EigenGAN which is able to unsupervisedly mine interpretable and controllable dimensions from different generator layers. Specifically, EigenGAN embeds one linear subspace with orthogonal basis into each generator layer. Via generative adversarial training to learn a target distribution, these layer-wise subspaces automatically discover a set of eigen-dimensions at each layer corresponding to a set of semantic attributes or interpretable variations. By traversing the coefficient of a specific eigen-dimension, the generator can produce samples with continuous changes corresponding to a specific semantic attribute. Taking the human face for example, EigenGAN can discover controllable dimensions for high-level concepts such as pose and gender in the subspace of deep layers, as well as low-level concepts such as hue and color in the subspace of shallow layers. Moreover, in the linear case, we theoretically prove that our algorithm derives the principal components as PCA does. |
@inproceedings{he2021eigengan,
title={EigenGAN: Layer-Wise Eigen-Learning for GANs},
author={He, Zhenliang and Kan, Meina and Shan, Shiguang},
booktitle={International Conference on Computer Vision},
year={2021}
} |
 | AttGAN: Facial Attribute Editing by Only Changing What You Want Zhenliang He, Wangmeng Zuo, Meina Kan, Shiguang Shan✉, Xilin Chen   ⮟ Abstract ⮝ Abstract | Paper | TensorFlow (Official) | PyTorch | PaddlePaddle | ⮟ Bib ⮝ Bib |
Facial attribute editing aims to manipulate single or multiple attributes on a given face image, i.e., to generate a new face image with desired attributes while preserving other details. Recently, generative adversarial net (GAN) and encoder-decoder architecture are usually incorporated to handle this task with promising results. Based on the encoder-decoder architecture, facial attribute editing is achieved by decoding the latent representation of a given face conditioned on the desired attributes. Some existing methods attempt to establish an attribute-independent latent representation for further attribute editing. However, such attribute-independent constraint on the latent representation is excessive because it restricts the capacity of the latent representation and may result in information loss, leading to over-smooth or distorted generation. Instead of imposing constraints on the latent representation, in this work we propose to apply an attribute classification constraint to the generated image to just guarantee the correct change of desired attributes, i.e., to "change what you want". Meanwhile, the reconstruction learning is introduced to preserve attribute-excluding details, in other words, to "only change what you want". Besides, the adversarial learning is employed for visually realistic editing. These three components cooperate with each other forming an effective framework for high quality facial attribute editing, referred as AttGAN. Furthermore, the proposed method is extended for attribute style manipulation in an unsupervised manner. Experiments on two wild datasets, CelebA and LFW, show that the proposed method outperforms the state-of-the-arts on realistic attribute editing with other facial details well preserved. |
@article{he2019attgan,
title={AttGAN: Facial Attribute Editing by Only Changing What You Want},
author={He, Zhenliang and Zuo, Wangmeng and Kan, Meina and Shan, Shiguang and Chen, Xilin},
journal={IEEE Transactions on Image Processing},
volume={28},
number={11},
pages={5464--5478},
year={2019}
} |
 | S2GAN: Share Aging Factors Across Ages and Share Aging Trends Among Individuals Zhenliang He, Meina Kan✉, Shiguang Shan, Xilin Chen  ⮟ Abstract ⮝ Abstract | Paper | Video | ⮟ Bib ⮝ Bib |
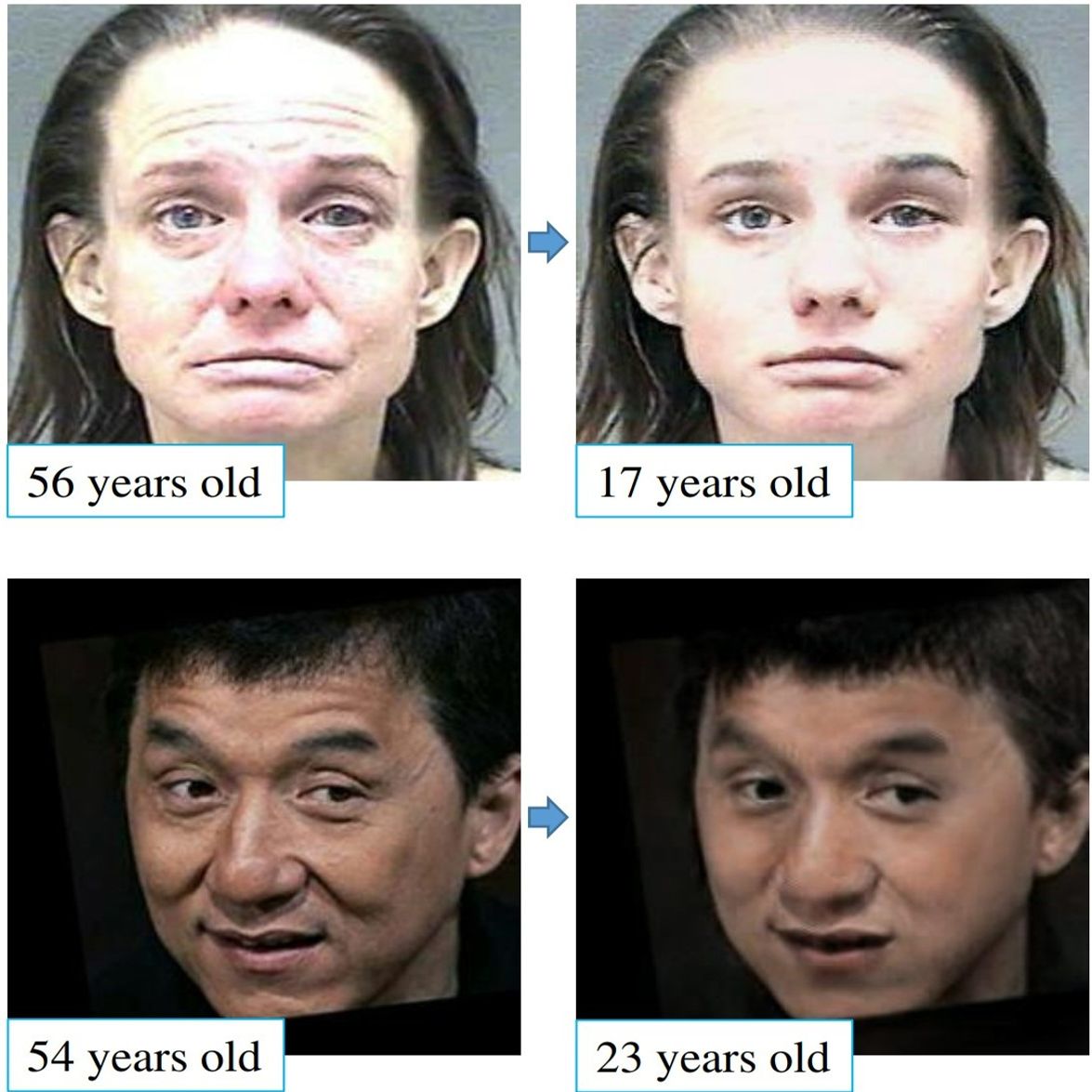
Generally, we human follow the roughly common aging trends, e.g., the wrinkles only tend to be more, longer or deeper. However, the aging process of each individual is more dominated by his/her personalized factors, including the invariant factors such as identity and mole, as well as the personalized aging patterns, e.g., one may age by graying hair while another may age by receding hairline. Following this biological principle, in this work, we propose an effective and efficient method to simulate natural aging. Specifically, a personalized aging basis is established for each individual to depict his/her own aging factors. Then different ages share this basis, being derived through age-specific transforms. The age-specific transforms represent the aging trends which are shared among all individuals. The proposed method can achieve continuous face aging with favorable aging accuracy, identity preservation, and fidelity. Furthermore, befitted from the effective design, a unique model is capable of all ages and the prediction time is significantly saved. |
@inproceedings{he2019s2gan,
title={S2GAN: Share Aging Factors Across Ages and Share Aging Trends Among Individuals},
author={He, Zhenliang and Kan, Meina and Shan, Shiguang and Chen, Xilin},
booktitle={International Conference on Computer Vision},
year={2019}
} |
 | PA-GAN: Progressive Attention Generative Adversarial Network for Facial Attribute Editing Zhenliang He, Meina Kan✉, Jichao Zhang, Shiguang Shan   ⮟ Abstract ⮝ Abstract | Paper | TensorFlow (Official) | ⮟ Bib ⮝ Bib |
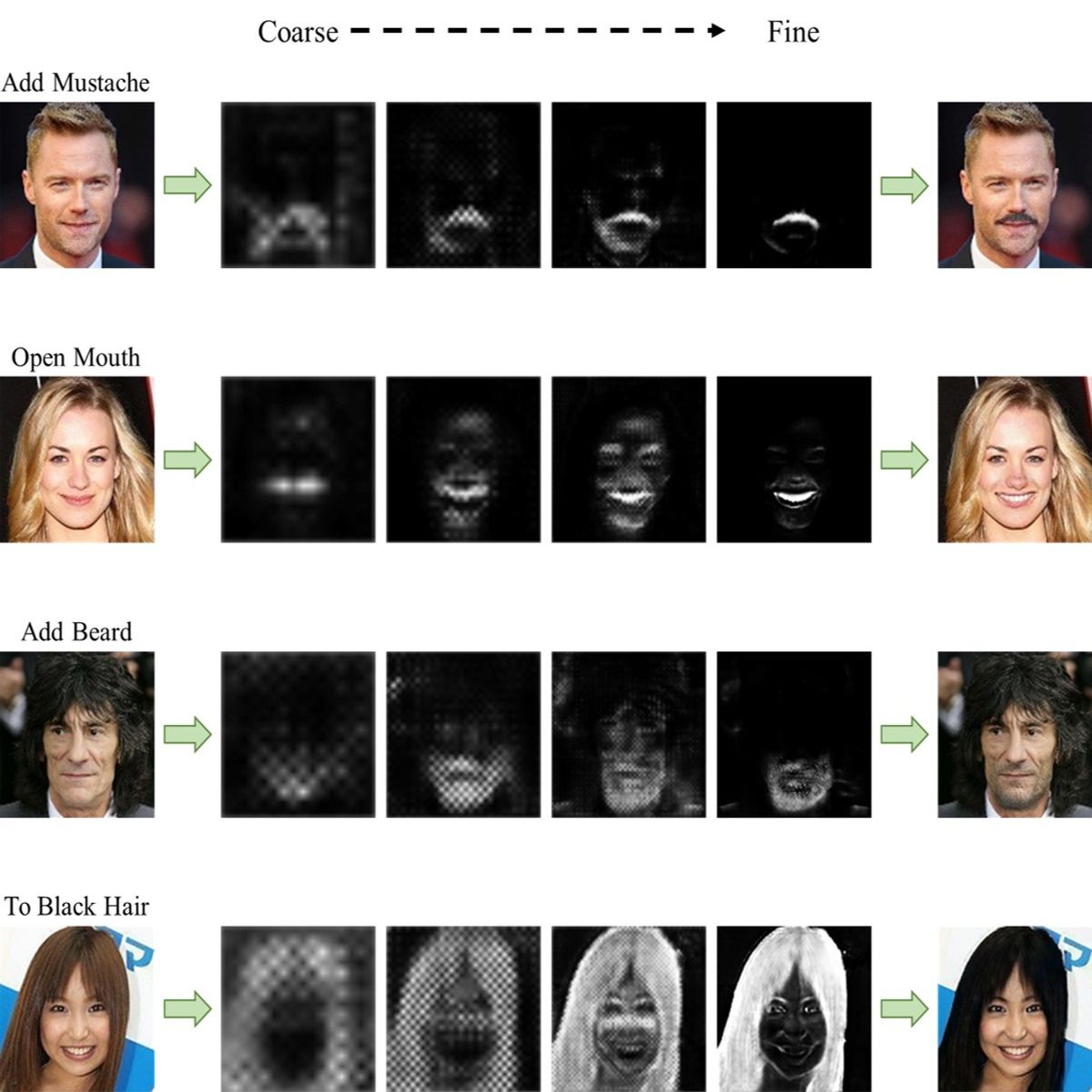
Facial attribute editing aims to manipulate attributes on the human face, e.g., adding a mustache or changing the hair color. Existing approaches suffer from a serious compromise between correct attribute generation and preservation of the other information such as identity and background, because they edit the attributes in the imprecise area. To resolve this dilemma, we propose a progressive attention GAN (PA-GAN) for facial attribute editing. In our approach, the editing is progressively conducted from high to low feature level while being constrained inside a proper attribute area by an attention mask at each level. This manner prevents undesired modifications to the irrelevant regions from the beginning, and then the network can focus more on correctly generating the attributes within a proper boundary at each level. As a result, our approach achieves correct attribute editing with irrelevant details much better preserved compared with the state-of-the-arts. |
@article{he2020pagan,
title={PA-GAN: Progressive Attention Generative Adversarial Network for Facial Attribute Editing},
author={He, Zhenliang and Kan, Meina and Zhang, Jichao and Shan, Shiguang},
journal={arXiv:2007.05892},
year={2020}
} |